
How to build a second brain with an AI agent (2026)
The agent does the filing, not you
I have built a second brain three times. The first two died the same way: I set up a beautiful vault, tagged everything for a month, then stopped touching it the week I got busy. Within a quarter it was a graveyard of stale notes I no longer trusted. The system asked me to be the librarian, and I am a bad librarian.
The version that finally stuck looks nothing like a vault I tend. It is a small set of memory files plus an AI agent that does the librarian work for me. The agent captures what matters from a session, files it into the right place, and pulls it back up before it acts. I stopped maintaining a second brain and started running one. This guide is exactly how I build that, step by step, so the brain maintains itself instead of slowly rotting while you are busy.
How to build a second brain with an AI agent
The shift that makes this work is simple to say and easy to skip: the agent is not just a thing that reads your second brain, it is the thing that builds and keeps it. In the old model you write the notes and the AI maybe reads them. In this model the AI writes the notes too, into a store it controls, and reads them back on every task. You become the editor, not the data-entry clerk.
To get there you need four things in place: a memory store the agent can both read and write, a memory file it loads every session, a capture habit the agent runs for you, and a recall step the agent takes before it acts. I cover the broad concept in the AI second brain guide, so here I am going to stay hands-on and walk the actual build. If you have never set up the underlying concept at all, read that first, then come back for the agent-run version.
Pick a memory store the agent can read and write
A note app is a dead end for this. Most note tools let the AI read a page if you paste it in, but the agent cannot reliably write back, file things into the right spot, or query across everything you have stored. For an agent to run your second brain, it needs a store it can both read from and write to on its own, through a real connection, not copy and paste.
In 2026 the standard way to give an agent that store is an MCP memory server. MCP, the Model Context Protocol, is the plug that lets an AI client like Claude reach an external tool, and a memory server is a tool whose job is holding and returning your knowledge. The agent gets a set of memory functions, write this fact, find facts about this client, list open decisions, and it calls them like any other tool. I broke down how this fits together in the second brain MCP guide. The practical point is that you want a store designed for an agent to drive, not a human-first app you bolt the AI onto.
The implementation I run is Iwo's Second Brain on top of Iwo's MemoryOS, which is an MCP memory server. It works with Claude Code, Claude Cowork, Claude Desktop, Cursor, and Windsurf, so the same brain follows me across whatever client I am in that day. The data lives in a local database on my machine rather than someone else's server, which matters once your brain holds client notes and private decisions.
The four parts of an agent-run second brain
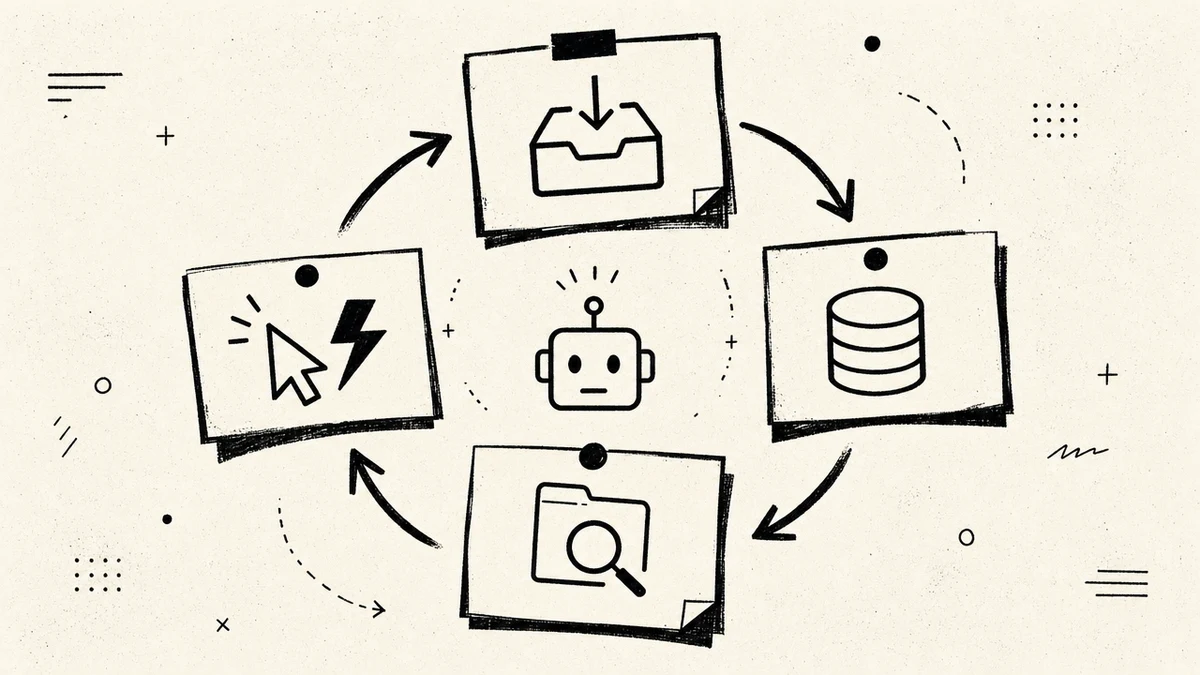
Once the store is in place, the system runs as a loop with the agent in the middle. There are four parts, and skipping any one of them is where a second brain quietly fails.
- Capture. The agent notices what is worth keeping from a session and writes it down, so good information stops evaporating when the chat ends.
- Store. That captured note lands in a structured place, filed by type, so it can be found again instead of buried in a transcript.
- Recall. Before the agent does a task, it queries the store for what it already knows, so it acts on your real context, not a blank slate.
- Act. The agent does the work with that context loaded, and anything new it learns feeds back into capture.
The reason this beats a vault you tend is that you are not in three of the four steps. You decide what good looks like and review the output. The agent runs capture, store, and recall on every pass, which is the boring upkeep that kills human-tended systems.
Give the agent a memory file it reads every session
The store holds the deep knowledge, but the agent needs a front door: one short file it loads at the start of every session. Think of it as the index card stapled to the front of the filing cabinet. Mine holds who I am, what I am working on this quarter, how I write, and a pointer that tells the agent to query the memory store before it starts real work.
This file does two jobs. It removes the re-explaining tax, the agent already knows my role and voice, and it teaches the agent the protocol: check memory first, file new facts as you go. In Claude Code this is a project memory file the tool loads automatically, and I wrote the full setup in how to build a second brain in Claude Code. The same idea works in any client that supports a persistent instruction file. Keep it short. A bloated memory file is just context you pay for on every single call, so it should point to the store, not duplicate it.
Set up capture so the agent files what matters
Capture is where the agent earns its keep. The goal is that you never again finish a useful conversation and think, I should write that down. The agent writes it down.
In practice I give the agent a standing instruction in the memory file: when we make a decision, learn a fact about a client, or leave something unfinished, save it to memory with the right type. Then I work normally. When I say, "we will go with the annual plan for that client," the agent files it as a decision without me asking. When I mention a deadline, it files it as an open loop. The capture rule lives in the memory file so it applies to every session, not just the ones where I remember to ask. This is the difference between a second brain you feed and one that feeds itself, and it is the part the persistent memory setup guide walks through end to end on MemoryOS.
Organize with typed surfaces, not one big pile
A common mistake is letting the agent dump everything into one undifferentiated notes blob. That recreates the original problem: you can store fast but you cannot recall precisely. The fix is typed surfaces, a small set of categories the agent files into, so a query can ask for one kind of thing.
The three types I rely on most:
- Decisions. What we chose and why. This is the surface that saves you from relitigating the same call three times.
- Facts. Stable truths about you, a project, or a client. The agent reads these to stop asking what it should already know.
- Open loops. Unfinished threads and commitments. The agent surfaces these so nothing falls through.
You do not need a sprawling taxonomy. A handful of types the agent understands beats a deep folder tree no one maintains. A good MCP memory store lets the agent write to a type and query a type, so "what did we decide about pricing" returns decisions, not every message that mentioned a number.
Make recall happen before the agent acts
Capture and storage are worthless if the agent forgets to look. The recall step is a one-line rule in the memory file that the agent should query the store for relevant context before it starts a task, not after it has already guessed.
This is the move that makes the brain feel alive. I ask the agent to draft a follow-up to a client, and instead of writing a generic email, it first pulls that client's facts, the last decision we made, and any open loop, then writes from that. I did not paste anything. The agent recalled it because the protocol says recall first. When recall is reliable, you stop being the integration layer between your own notes and the work, which is the entire promise of building a second brain with an AI agent in the first place.
Let the agent maintain it
The last piece is the one that saved my third attempt: upkeep runs without me. A second brain rots because facts go stale, decisions get superseded, and open loops get closed but never marked. If a human has to catch all of that, the system dies on the first busy week.
So I push the maintenance onto the agent and the store. The shape is a small pipeline: a trigger happens in a session, the agent files the new state into the right typed surface, and recall later returns the current version, not the outdated one. On MemoryOS this is what the monitoring layer is for, it watches for knowledge that has decayed or references that no longer resolve and flags or fixes them, so the brain stays trustworthy without me auditing it by hand. The standard tier on Iwo's MemoryOS runs that ambient monitoring for $199 a year, with a free Health Check if you just want to score what you already have before committing. Pricing is current as of mid-2026 and moves often, so confirm before you commit.
How to start this week
You can stand up a working version in an afternoon. Here is the order I would do it in.
- Connect a memory store the agent can write to. Set up an MCP memory server so your agent has read and write functions, not just a doc it can read.
- Write the memory file. One short file with your role, your current work, your voice, and three rules: recall before acting, capture decisions and facts and open loops, file by type.
- Run one real session and let it capture. Do actual work and watch the agent file things. Correct what it miscategorizes once, and it learns the pattern.
- Test recall on a fresh session. Start clean and ask it something that depends on last session's notes. If it pulls the right context without you pasting, the loop is closed.
- Turn on upkeep. Let the store flag stale facts and superseded decisions so you are not the one auditing.
If you do not want to wire each piece by hand, Iwo's Second Brain ships the store, the typed surfaces, and the agent protocol as a template, so you start at step three instead of step one.
Mistakes that keep the agent from running it
I have hit every one of these, usually more than once.
- Using a read-only store. If the agent cannot write back, you are still the data-entry clerk and the system will rot the moment you get busy. The store has to be writable by the agent.
- One giant notes blob. Without typed surfaces, recall returns noise and you stop trusting it. Give the agent decisions, facts, and open loops to file into.
- No recall rule. If the memory file does not tell the agent to check memory first, it will happily answer from a blank slate while a perfect note sits unread.
- A bloated memory file. Stuffing the whole brain into the always-loaded file makes every call slower and more expensive. The file points to the store, it is not a copy of it.
- Never reviewing. Hands-off does not mean blind. Skim what the agent filed for the first week so you trust the surfaces before you lean on them. For the team version of this same setup, see the company second brain with AI agents post.
FAQ
What is the difference between a second brain and an AI agent second brain?
A classic second brain is a knowledge store you maintain by hand, notes you write, tag, and organize yourself. An AI agent second brain puts the agent in charge of the upkeep: it captures notes from your sessions, files them into typed surfaces, and recalls them before it acts. You shift from librarian to editor. The store still holds the knowledge, but you are no longer the one keeping it tidy.
Do I need to know how to code to build this?
No. The hardest part is connecting an MCP memory server to your AI client, and that is configuration, not programming. Writing the memory file is plain English: your role, your projects, and a few rules about when to recall and capture. A packaged option like Iwo's Second Brain on MemoryOS handles the store and the protocol so you mostly write instructions, not code.
What is an MCP memory server and why does the agent need one?
MCP, the Model Context Protocol, is a standard that lets an AI client connect to external tools. A memory server is a tool whose job is storing and returning your knowledge. The agent needs it because a note app usually only lets the AI read pasted text, while an MCP memory server gives the agent functions to write facts, file by type, and query across everything, which is what makes the agent able to run the brain instead of just reading it.
How does the second brain stay up to date without me maintaining it?
The agent files new state into the store as you work, so the current decision or fact overwrites the stale one, and recall returns the latest version. On a store with a monitoring layer, like MemoryOS, the system also flags knowledge that has decayed or references that no longer resolve, so trust does not depend on you auditing the brain by hand. Your job drops to a quick review, not constant tending.
Which AI tools can I use to build a second brain with an AI agent?
Any client that supports MCP and a persistent instruction file. I run mine across Claude Code, Claude Cowork, Claude Desktop, Cursor, and Windsurf, with the same MemoryOS store behind all of them, so the brain follows me regardless of which tool I open. The memory file and the typed surfaces work the same way in each.
How is this different from just turning on memory in ChatGPT or Claude?
Built-in chat memory is convenient but shallow: it captures loosely, you cannot see or organize what it kept, and it does not file by type or follow you across tools. An agent-run second brain on an MCP store is explicit, you control the surfaces, the agent files deliberately, and recall is a queryable step. You trade a little setup for a brain you can actually trust and inspect.
A second brain only compounds if something keeps it alive, and that something should not be you on your busiest week. Iwo's Second Brain ships the agent-run version as a template, on Iwo's MemoryOS so capture, recall, and upkeep run on their own. For the broader concept first, read the AI second brain guide.