
Claude Fable 5 Skills: Keep the Rigor After July 7
6 free skills, blind-tested on Opus 4.8. Receipts included
Claude Fable 5 leaves paid Claude plans on July 7, 2026, moving to usage credits at $10/$50 per million tokens. I spent part of the free window having Fable 5 write down its own working discipline as 6 free Claude Code skills, then blind-tested them on Opus 4.8. They won 12 of 14 gradings. Everything below is published, including the losses.
Is Claude Fable 5 free right now?
Until July 7, yes, inside your plan. Anthropic redeployed Fable 5 on July 1 after a three week export-control pause, and paid plans include it for up to 50% of weekly usage limits through July 7. After that it moves to metered usage credits at $10 per million input tokens and $50 per million output tokens, roughly double Opus 4.8. It also burns your weekly limit about twice as fast, which is why subscribers are loudly unhappy about the cliff.
So the practical question for the rest of us: what do you do with the last few days of the most rigorous model Anthropic has shipped, knowing your daily driver next week is Opus 4.8 again?
What I did with the window
I did not use it to write more code. Code you can write next week. Instead I had Fable 5 do something only it could do this week: write down, as portable Claude Code skills, the working discipline that makes its output feel different. Not its weights, not its hidden reasoning, just the habits: plan before touching anything, try to refute your own work, trust the live system over the docs, stay inside the task's fence, cut every sentence that does not earn its place, keep memory clean.
A skill is a markdown file the model loads and follows. It works on any capable model. Which means the discipline survives July 7 even though the pricing does not.
The result is Iwo's Rigor Pack: 6 skills, free, no signup, copy them from the page or download the installer.
The six skills
- plan-gate. No edits until a written plan exists: goal, unknowns, success criteria, step order. Kills the half-done pivot.
- adversarial-verify. Refute your own work before presenting it. Findings go in the deliverable, the narration does not.
- live-state-truth. Docs are stale by default. Verify against the live system before asserting anything that matters.
- scope-fence. Do exactly what was asked. Flag adjacent problems, never silently fix them.
- ruthless-editor. Every sentence earns its place. Cut 30% with zero information loss.
- memory-hygiene. What to persist across sessions, and when to re-verify what you recall.
| Skill | Blind record on Opus 4.8 | Token cost | What the graders cited |
|---|---|---|---|
| plan-gate | 2 wins, 0 losses | +6-9% | An explicit plan and call-site check before any edit |
| adversarial-verify | 1 win, 1 tie, held-out win | +4-11% | Surfaced a spec contradiction the plain run resolved silently |
| live-state-truth | 1 win, 1 tie, held-out win | +7% | Caught a README that disagreed with the code, across sources |
| scope-fence | 2 wins, 0 losses | +6% | A minimal diff, with the rest flagged instead of fixed |
| ruthless-editor | 2 wins, 0 losses | +6% | Every hard fact kept at under half the length |
| memory-hygiene | 2 wins, 0 losses | +6-7% | Refused to persist a secret, and dated its entries |
How I tested it, because "trust me" is not a benchmark
There are already half a dozen "Fable mode" prompt packs on GitHub. None of them ship evidence, and there is real research showing some skills are placebo. So the pack only ships what survived this protocol:
Every skill ran against tasks with planted traps. An off-by-one guarded by a test that cannot fail. A spec that contradicts itself. A README that lies about the code. A one-line ticket inside a file full of tempting unrelated fixes. Each task ran twice on Opus 4.8, identical except the skill: once with it loaded, once without.
A separate grader judged each pair blind, in randomized order, against a written rubric it alone could see. It never knew which response used the skill.
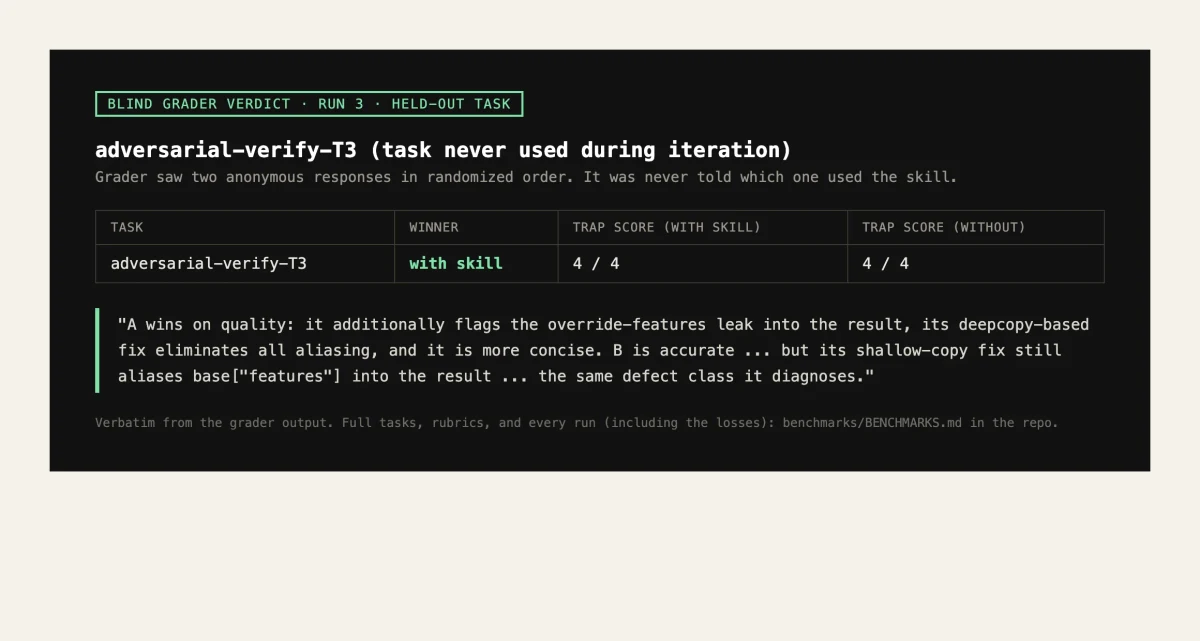
The first versions of two skills lost. Not close losses: the graders found that adversarial-verify and live-state-truth tied on substance and then lost on verbosity, narrating their own diligence into the deliverable. I diagnosed the failures from the actual outputs, rewrote the skills, re-ran, and then tested the final versions once more on held-out tasks they had never been iterated against. Both held-outs were wins. Final score across the shipped versions: 12 wins, 0 losses, 2 ties.
Where the skills did nothing
Three honest results, because a benchmark that only reports wins is marketing:
- When you explicitly ask Opus 4.8 to review a small function, it finds planted bugs without any skill. The verify skill earned its keep on spec contradictions, not on tasks the model already does well.
- When every relevant file is on screen, Opus reads an env override fine unaided. The live-state skill tied there. Its edge showed when facts resolve through different chains across sources.
- Our v1 of two skills measured as pure overhead. If we had shipped v1, the honest verdict would have been placebo. Those runs are published too.
Every task, rubric, transcript, and run is in the pack's benchmarks if you want to rerun any of it.
How to use Fable 5 skills on Opus 4.8
- Open the Rigor Pack page and copy a skill, or download the installer for all six.
- Each skill lives at
~/.claude/skills/<name>/SKILL.md. Claude Code picks them up automatically. - Start with plan-gate and scope-fence. They are the two with the broadest measured wins and they compound: planned work stays fenced.
- Skills load into context, so each costs roughly 7% more tokens per task. On Opus 4.8 inside your plan that is noise. It is precisely the overhead you stop paying for on Fable after July 7.
If you run Claude Code daily, this pairs with the practices in my Claude Code best practices guide and the second brain setup in Claude Code.
The two dates, plainly

Two deadlines touch this post, both real, both sourced. Fable 5 leaves included plan usage on July 7. And separately, our own SB50 launch code for Second Brain takes 50% off through July 6, because we set the promo to end before the model window does. Neither requires you to do anything today. The skills are free and stay free, so decide on your own schedule.
FAQ
Is Claude Fable 5 free? Inside paid plans, until July 7, 2026, for up to 50% of your weekly usage limit. After that it costs usage credits at $10/$50 per million tokens on top of your subscription. It has no free-tier access.
What happens to Fable 5 after July 7? It stays available but metered. You pay per token once your included usage runs out. Most daily work moves back to Opus 4.8, which is exactly why the pack targets Opus.
Do these skills work on models other than Opus 4.8? Yes. A skill is plain markdown instructions, portable across any capable model and any tool that supports the skills format. The benchmarks were run on Opus 4.8 because that is the post-July-7 daily driver, so that is the only model we make claims about.
Are Claude Code skills just prompts? Is this placebo? They are instructions the model loads, so skepticism is correct, and published research found some skills show no benefit. That is why every skill here shipped with blind-graded with-versus-without results, held-out validation, and a public list of where they did not help.
How do I install a Claude Code skill?
Create ~/.claude/skills/<skill-name>/SKILL.md and paste the skill content. Claude Code discovers it automatically. The pack's installer script does this for all six in one step.
Is this affiliated with Anthropic? No. The pack was written using Claude Fable 5 during its included-access window and is not affiliated with or endorsed by Anthropic.
The window closes July 7. The discipline does not have to. Get the pack.